

Mon projet nécessite-t-il une phase d'annotation et quelle stratégie d'annotation adopter ?
Beaucoup de projets réalisés à partir de données non structurées nécessitent une phase d'annotation, le recours à l'annotation n'est pourtant pas systématique. A cette question préalable de la nécessité ou non d'une phase d'annotation, s'ajoute celle de la stratégie d'annotation à adopter : annoter la totalité du corpus de données à la main ou automatiser le processus d'annotation ?
Bien connaître son corpus de données
Il faut dans un premier temps prendre en compte la nature des données à analyser :
Les données sont-elles structurées, semi-structurées, non structurées ?
Est-ce un stock de données historiques qui ne sera pas réalimenté dans le futur ou un flux de données alimenté en continu ?
Quel est le volume total des données ?
Les réponses à ces différentes questions seront déterminantes pour les choix à effectuer en termes d'annotation : dois-je annoter ou non ? Quelle stratégie d'annotation adopter ? Nous revenons d'abord sur la différence entre annotation manuelle et annotation automatique, puis nous présenterons les différentes façons d'automatiser l'annotation.
Différence entre annotation manuelle et annotation automatique
L'annotation manuelle est la tâche réalisée par un humain qui consiste à attribuer un label à un document ou à un sous ensemble d'un document. On parle d'annotation automatique lorsque cette tâche est réalisée par un programme informatique. L'automatisation de l'annotation peut être réalisée à l'aide de différentes méthodes. On distingue parmi les méthodes les plus courantes :
les moteurs de règles
les algorithmes d'apprentissage supervisé qui nécessitent une phase d'annotation au préalable
Ces méthodes, ainsi que dans quels cas de figures elles sont appropriées, sont détaillées dans la suite de cette partie.
Annoter à l'aide d'un moteur de règles permet dans certaines situations de se passer d'annotation manuelle
L’annotation manuelle est une tâche longue et coûteuse, il est donc important de ne pas se lancer tête baissée dans une phase d'annotation. Les données structurées sont souvent complexes à analyser, ce qui rend nécessaire une phase d'annotation pour les structurer. Il arrive cependant que des données en apparence non structurées présentent des régularités fortes qui permettent d'automatiser la structuration de l'information qu'elles contiennent en ayant recours à un ensemble de règles prédéfinies et donc de se passer d'annotation.
On parle alors de structuration de la donnée ou d'annotation par moteur de règles.
Un moteur de règles est un ensemble de règles prédéfinies « à l'avance ». Par exemple, une règle de pseudonymisation pourrait être « si le mot qui suit "Monsieur" ou "Madame" commence par une majuscule, alors ce mot est un prénom ». La complexité du langage naturel et la diversité des formulations rencontrées dans les documents fait que ce type de moteur de règles a de fortes chances de faire beaucoup d'erreurs dans des textes complexes, ou dont la forme varie souvent. :::
Concrètement, avec un moteur de règles, le passage de la donnée non-structurée à de la données structurée se fait par un programme informatique qui implémente des règles déterministes. Si cette méthode fournit des résultats satisfaisants, elle s'avère alors beaucoup moins coûteuse que l'annotation manuelle. Si en revanche, un moteur de règles ne permet pas d'attendre des résultats avec le niveau de précision souhaité, vous devrez probablement avoir recours à l'annotation manuelle. Nous verrons dans la partie Conduire votre campagne d'annotation comment les moteurs de règles, lorsqu'ils ne donnent pas de résultats assez satisfaisant pour se passer d'annotation, peuvent tout de même permettre d'accélérer le processus d'annotation grâce à la pré-annotation.
Exemple avec des données textuelles : Extraction d'informations à partir de formulaires au format word Vous disposez d'un ensemble de documents textuels comme des réponses à un questionnaire. Vous cherchez à extraire un certain nombre d'informations de ces documents (nom, prénom, adresse par exemple). Des règles informatiques simples de recherche textuelle (le texte entre "Nom" et "Prénom" permet d'extraire le nom, le texte entre "Prénom" et "Adresse" permet d'extraire le prénom) peuvent dans certains cas permettre d'extraire les informations.
Exemple avec des données images : anonymisation des bulletins de salaires scannés Vous disposez de bulletins de salaire au format image que vous souhaitez anonymiser (par exemple, retirer les données à caractère personnel comme les noms, prénoms, adresses). Il est très probable que tous les bulletins aient le même format et donc que les informations à retirer se retrouvent précisément au même endroit de l'image. Appliquer des règles déterministes du type mettre un carré noir de taille lxL aux coordonnées xy permet d'éviter de recourir à une annotation manuelle de tous les documents, qui reviendrait à demander à une personne, à l'aide d'un outil d'annotation d'image, d'identifier sur chaque document les endroits où se trouvent les informations à caractère personnel.
Automatiser l'annotation manuelle à l'aide de l'intelligence artificielle (IA): dans quels cas est-ce pertinent ?
Si le volume des données est relativement limité, il n’est pas nécessairement pertinent d’envisager des méthodes d’IA pour structurer la donnée. Par exemple, vous souhaitez analyser les réponses en texte libre à un questionnaire, afin d’en tirer des conclusions précises sur les thématiques abordées par les répondants. Si le volume des données est faible, une étape d’annotation seule pourra répondre à votre objectif sans être trop coûteux en temps. Nous ne donnons pas ici de seuil de nombre de documents permettant de juger de la pertinence ou non de la mise en place de solutions d’IA car l’évaluation du temps nécessaire à l’annotation manuelle du jeu de données dépendra de la nature et de la longueur des documents, ainsi que de la complexité de la tâche d’annotation.
En revanche, si l’on est confronté à un volume important de documents ou à un flux continu de documents, il est en général pertinent d’envisager d’automatiser le processus d’annotation. Dans ce cas, la phase d’annotation aura pour objectif d’annoter une partie des documents (encore une fois, le volume nécessaire de documents annotés dépendra de la nature des documents et de la complexité de la tâche) afin d’entraîner un algorithme supervisé à automatiser cette tâche.
Pour résumer, voici un schéma du questionnement à suivre pour déterminer si un projet nécessite ou non une phase d'annotation et choisir la bonne stratégie d'annotation.
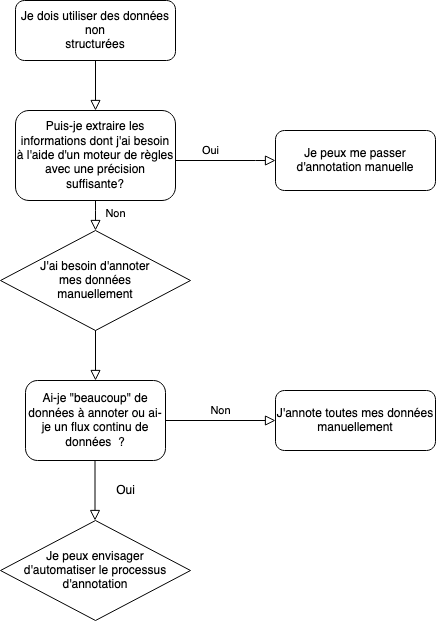
Schéma du questionnement à suivre pour déterminer si un projet nécessite une phase d'annotation
Ce schéma simplifie une réalité souvent plus complexe, et vous pourrez en pratique être amené à tester différentes méthodes, voire à combiner ces différentes méthodes. Par exemple, un moteur de règles pourra s'avérer insuffisant en termes de performance mais pourra être utile comme aide à l'annotation. On parle alors de pré-annotation (sujet qui sera détaillé dans la partie Conduire votre campagne d'annotation). De plus, la plupart des questions n'ont en général pas de réponses univoques, en particulier :
"Puis-je extraire les informations dont j'ai besoin à l'aide d'un moteur de règles avec une précision suffisante ?" : la question du seuil de précision minimale résulte souvent d'un arbitrage avec d'autres variables et en particulier avec les ressources à disposition pour l'annotation
"Ai-je beaucoup de données à annoter ou ai-je un flux continu de données ?" Le seuil maximal de données dépendra notamment de la complexité de la tâche d'annotation, des ressources disponibles pour l'annotation manuelle comparées aux ressources pour l'automatisation.
Annoter ou repenser la façon de collecter la donnée ?
Le besoin en annotation peut parfois mettre en lumière un mode de collecte de la donnée qui n'est pas adapté aux besoins des utilisateurs. Le travail d'annotation ex post aurait parfois pu être évité en intégrant un processus de structuration de la donnée ex ante, cette dernière solution permettant un gain de temps souvent significatif par rapport à la première.
::: tip Par exemple, l'enregistrement dans un système d'information d'une procédure ou d'une déclaration est réalisé via une application permettant à des agents de remplir un certain nombre de champs. Certains champs à remplir en texte libre peuvent ainsi nécessiter une annotation ex post afin d'utiliser l'information qu'ils contiennent alors que la même information aurait pu être saisie via un menu déroulant comportant une liste prédéfinie de champs pour être directement exploitable. :::
Exemples de projets d'intelligence artificielle comportant une phase d’annotation
Les exemples de projets comportant une phase d'annotation sont nombreux. Par exemple plus de la moitié des projets sélectionnés dans le cadre de l'Appel à Manifestation d'Intérêt pour l'intelligence artificielle (AMI IA 1 et AMI 2) ont nécessité une phase d'annotation. Cette section présente quelques exemples dans le secteur public.
PIAF (Pour des IA Francophones)
Le projet en quelques chiffres :
Le projet : Annoter des paragraphes Wikipedia afin de constituer une jeu de données francophone de questions-réponses
Le temps moyen pour annoter un paragraphe : eniron 5 min par paragraphe
L'équipe d'annotateurs : équipe de contributeurs volontaires ( 640 contributeurs en septembre 2020)
Le nombre de paires de questions-réponses réalisées en septembre 2020: 8640
Le schéma synthétique d'annotation : trouver 5 questions portant sur un paragraphe donné et souligner la réponse correspondante dans le texte du paragraphe
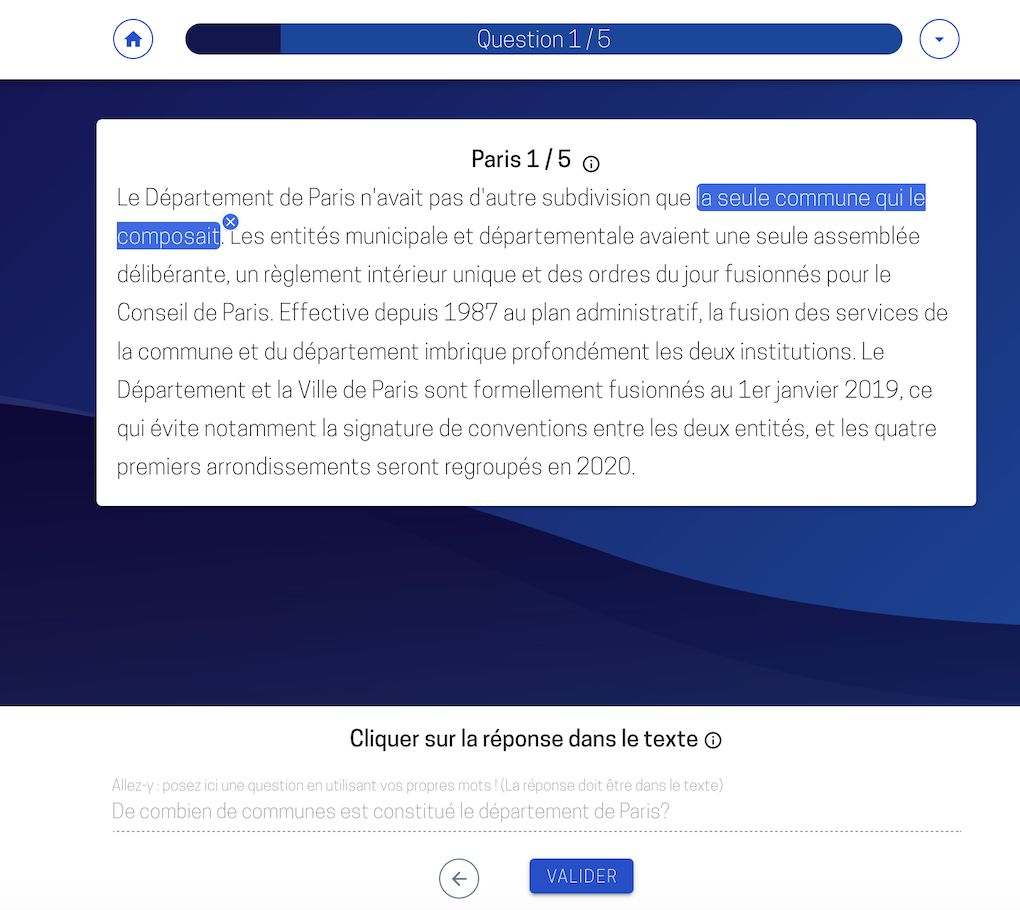
Capture d'écran de la plateforme d'annotation Piaf, en bas de l'écran, un exemple d'une question rédigée par un annotateur et de la réponse correspondante que l'annotateur doit souligner dans le texte en haut de l'écran
PIAF est un projet porté par le Lab IA d'Etalab qui a pour but de constituer un jeu de données francophone pour entraîner des algorithmes d’intelligence artificielle (IA) de questions-réponses. Ces derniers permettent de trouver des réponses à des questions précises portant sur un ensemble de documents. Construire des algorithmes performants de questions-réponses (question-answering en anglais) compte aujourd’hui parmi les tâches les plus complexes du traitement du langage naturel. Or avant le lancement du projet en 2019, il n'existait pas de jeu de données de ce type en français. Les algorithmes de questions-réponses sont pourtant utiles dans beaucoup de domaines, et les cas d'usage sont nombreux, on y compte par exemple la création d'agents conversationnels ou l'amélioration de moteurs de recherche en permettant des réponses plus ciblées.
La tâche d'annotation consiste ici à annoter des paragraphes de Wikipédia. Pour chaque paragraphe, l'annotateur a pour tâche de trouver cinq questions portant sur le paragraphe et y souligner la réponse correspondante. Pour plus d'information, vous pouvez vous référer au protocole d'annotation. Une plateforme d'annotation a été développée et permet à toute personne francophone d'annoter des paragraphes afin d'alimenter le jeu de données. Nous reviendrons plus tard sur cette méthode de crowd sourcing des annotations.
La pseudonymisation des décisions de justice à la Cour de Cassation
Le projet en quelques chiffres :
Le volume de documents : 180 000 décisions (bases de données « Jurinet » et « Jurica ») par an, un stock de 3 millions de décisions de justice à diffuser
Le temps moyen pour annoter un document : entre 5 et 10 min par décision
L'équipe d'annotateurs : 10 ETP à temps plein
Le schéma synthétique d'annotation : nom et prénom de personne physique, date de naissance, adresse
Résultats obtenus : l'algorithme d'IA développé permet d'obtenir un taux d'erreur moyen de 1%
La Cour de Cassation est chargée de la diffusion des décisions de justice. Le périmètre de diffusion est étendu depuis la publication du décret sur l'Open Data des décisions de justice. Cette diffusion ne peut cependant se faire qu'après avoir occulté des décisions de justice les éléments à caractère personnel. Afin de mettre en œuvre cette occultation, la Cour de Cassation a recours à une équipe d'une dizaine d'annotateurs afin d'identifier dans les décisions les éléments à caractère personnel (noms, prénoms, adresses, dates de naissance), qui doivent être retirés avant diffusion. Afin d'automatiser ce processus, la cour de cassation à fait appel à des data scientists via le programme Entrepreneurs d'Intérêt Général pour développer une solution d'Intelligence Artificielle de pseudonymisation des décisions : c'est le projet Open Justice. Cette solution est basée sur un algorithme entraîné à partir d'un corpus de décisions annotées manuellement. Afin d'optimiser le processus d'annotation, la Cour de cassation va développer un logiciel d'annotation via le projet Label.
Pour plus d'information sur la pseudonymisation de documents textuels à l'aide de méthodes d'intelligence artificielle, vous pouvez consulter notre guide pseudonymisation.
Projet DDTM Hérault : annotation d'images satellites
Le projet en quelques chiffres :
Le projet: Développer un outil d'intelligence artificielle capable de repérer automatiquement les constructions illégales
L'équipe d'annotateurs : 4 agents sur une période de 4 semaines, à raison d'1 à 2 heures par jour
Volume de documents annotés: 6 000 images
Le schéma synthétique d'annotation : caravane, mobiles homes, construction en dur, construction légère, piscine, décharge, déchets industriels, navires

Une capture d'écran du logiciel d'annotation développé pour la DDTM de l'Hérault
Ce projet, réalisé dans le cadre de la première saison de l'Appel à Manifestation d'Intérêt en Intelligence Artificielle à la DDTM de l'Hérault , vise a développer un modèle d’analyse d’images aériennes ou satellites pour automatiser le pré-repérage des infractions potentielles liées à la cabanisation. Cette automatisation nécessite une phase d'annotation manuelle d'images satellites. La tâche d'annotation consiste à repérer sur l'image les zones correspondant à plusieurs types d'objet (caravanes, mobile homes, constructions en dur, piscines, navires) et à leur attribuer le label correspondant. Un logiciel d'annotation d'image a été développé à cet effet.
Mis à jour
Ce contenu vous a-t-il été utile ?